mBART is another transformer model pretrained on so much data that no mortal would dare try to reproduce. This model is special because, like its unilingual cousin BART, it has an encoder-decoder architecture with an autoregressive decoder. Having been trained on 25 languages, this opens the door to a ton of generative text applications that, so far, have only been possible in English.
Luckily the authors released the code and checkpoints so we can play with this and the most obvious application is to fine-tune this checkpoint for translation between a pair of languages. I’ve wanted to get my hands on a really good English-Japanese translation model for a while but there are no good checkpoints publicly available (I guess this has actual commercial value). With mBART I can train one myself for relatively cheap (around 12 hours on a P100 machine, one day total since we train each direction separately). Training an equivalent model from scratch would require weeks of training, and probably much more labeled data than is publicly available.
The official instructions, however, are very unclear if you’ve never used fairseq before, so I am posting here a much longer tutorial on how to fine-tune mBART so you don’t need to spend all the hours I did poring over the fairseq code and documentation :)
The model
I recommend you read the paper as it’s quite easy to follow. The basic idea is to train the model using monolingual data by masking a sentence that is fed to the encoder, and then have the decoder predict the whole sentence including the masked tokens.
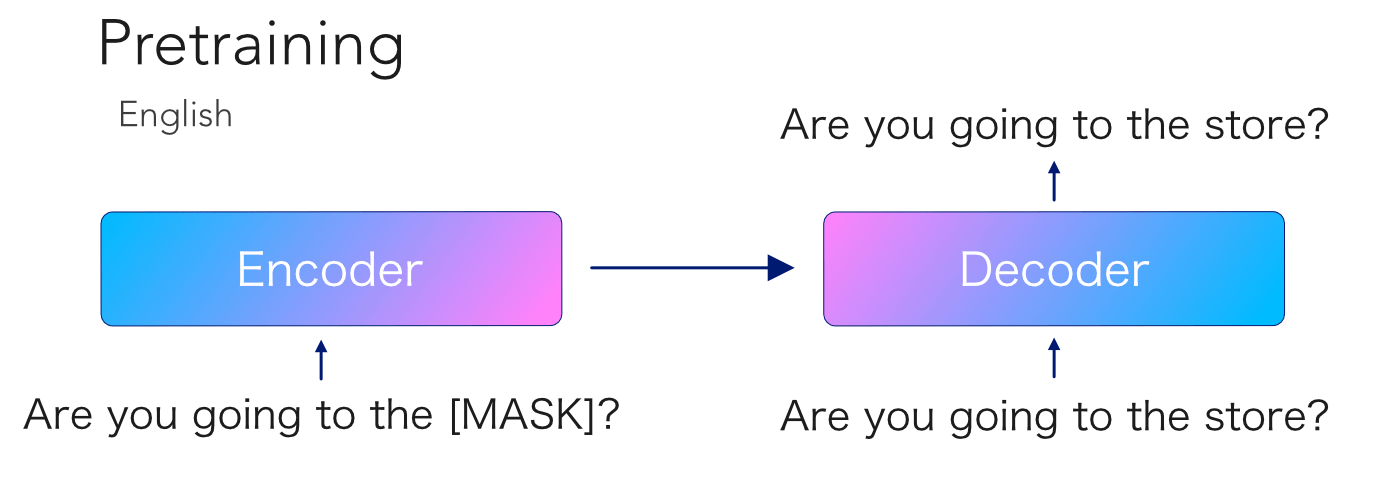
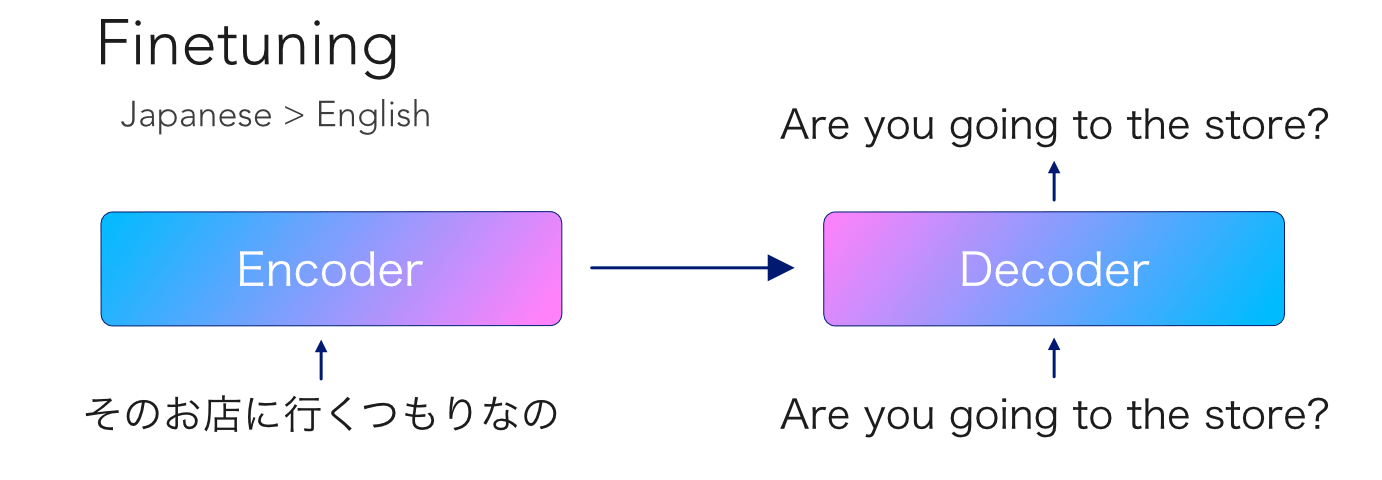
They trained this model on a huge dataset of Common Crawl data for 25 languages. So the autoregressive decoder should have a good prior of the structure of those languages. At fine-tuning time, we feed a full non-masked sentence to the encoder, and ask it to decode the corresponding pair in the other language.
Let’s do this
I assume you are doing this on a linux machine with a modern python interpreter and CUDA installed etc. If you are using an image from GCP or AWS you should in reasonably good shape. First we set up a virtual environment and install all the dependencies.
python -m venv nlp
source nlp/bin/activate
pip install pytorch
git clone fairseq
cd fairseq
pip install .
We also need to install the sentencepiece binary. I followed the instructions to compile from C++. After installation, the binary should be in /usr/local/bin/spm_encode.
Let’s also download the pretrained checkpoint.
wget https://dl.fbaipublicfiles.com/fairseq/models/mbart/mbart.CC25.tar.gz
tar -xzvf mbart.CC25.tar.gz
Datasets
We need some parallel aligned data to do the finetuning. Luckily we can find a lot of parallel aligned sentences in the WikiMatrix repo. Download your favorite language pair and untar it.
wget https://dl.fbaipublicfiles.com/laser/WikiMatrix/v1/WikiMatrix.en-ja.tsv.gz
Fairseq expects the data to be found in two separate files, one for each language, with one sentence of each pair per line. We need to split the data appropriately and also create train/test/validation splits. I wrote some python code so you don’t have to.
from tqdm import tqdm, trange
from sklearn.model_selection import train_test_split
en_data = []
jp_data = []
with open('WikiMatrix.en-ja.tsv') as fp:
for line in tqdm(fp, total=3895992):
line_data = line.rstrip().split('\t')
en_data.append(line_data[1] + '\n')
jp_data.append(line_data[2] + '\n')
total_test = 60000
en_train, en_subtotal, jp_train, jp_subtotal = train_test_split(
en_data, jp_data, test_size=total_test, random_state=42)
en_test, en_val, jp_test, jp_val = train_test_split(
en_subtotal, jp_subtotal, test_size=0.5, random_state=42)
file_mapping = {
'train.en_XX': en_train,
'train.ja_XX': jp_train,
'valid.en_XX': en_val,
'valid.ja_XX': jp_val,
'test.en_XX': en_test,
'test.ja_XX': jp_test,
}
for k, v in file_mapping.items():
with open(f'preprocessed/{k}', 'w') as fp:
fp.writelines(v)
Now we need to tokenize the data with sentencepiece (replace SRC, TGT and NAME with your own languages):
SPM=/usr/local/bin/spm_encode
MODEL={BASEDIR}/mbart.cc25/sentence.bpe.model
DATA={BASEDIR}/preprocessed
TRAIN=train
VALID=valid
TEST=test
SRC=en_XX
TGT=ja_XX
${SPM} --model=${MODEL} < ${DATA}/${TRAIN}.${SRC} > ${DATA}/${TRAIN}.spm.${SRC} &
${SPM} --model=${MODEL} < ${DATA}/${TRAIN}.${TGT} > ${DATA}/${TRAIN}.spm.${TGT} &
${SPM} --model=${MODEL} < ${DATA}/${VALID}.${SRC} > ${DATA}/${VALID}.spm.${SRC} &
${SPM} --model=${MODEL} < ${DATA}/${VALID}.${TGT} > ${DATA}/${VALID}.spm.${TGT} &
${SPM} --model=${MODEL} < ${DATA}/${TEST}.${SRC} > ${DATA}/${TEST}.spm.${SRC} &
${SPM} --model=${MODEL} < ${DATA}/${TEST}.${TGT} > ${DATA}/${TEST}.spm.${TGT} &
And then precalculate the indices for all tokens before training:
DATA={BASEDIR}/preprocessed
FAIRSEQ={BASEDIR}/fairseq
TRAIN=train
VALID=valid
TEST=test
SRC=en_XX
TGT=ja_XX
NAME=en-ja
DEST={BASEDIR}/postprocessed
DICT={BASEDIR}/mbart.cc25/dict.txt
python ${FAIRSEQ}/preprocess.py \
--source-lang ${SRC} \
--target-lang ${TGT} \
--trainpref ${DATA}/${TRAIN}.spm \
--validpref ${DATA}/${VALID}.spm \
--testpref ${DATA}/${TEST}.spm \
--destdir ${DEST}/${NAME} \
--thresholdtgt 0 \
--thresholdsrc 0 \
--srcdict ${DICT} \
--tgtdict ${DICT} \
--workers 70
Training
For training we can just follow the directions in the actual repo, modulo some typos. The command below should work if you followed the above
FAIRSEQ={BASEDIR}/fairseq
PRETRAIN={BASEDIR}/mbart.cc25/model.pt
langs=ar_AR,cs_CZ,de_DE,en_XX,es_XX,et_EE,fi_FI,fr_XX,gu_IN,hi_IN,it_IT,ja_XX,kk_KZ,ko_KR,lt_LT,lv_LV,my_MM,ne_NP,nl_XX,ro_RO,ru_RU,si_LK,tr_TR,vi_VN,zh_CN
SRC=en_XX
TGT=ja_XX
NAME=en-ja
DATADIR={BASEDIR}/postprocessed/{NAME}
SAVEDIR=checkpoint
python ${FAIRSEQ}/train.py ${DATADIR} --encoder-normalize-before --decoder-normalize-before --arch mbart_large --task translation_from_pretrained_bart --source-lang ${SRC} --target-lang ${TGT} --criterion label_smoothed_cross_entropy --label-smoothing 0.2 --dataset-impl mmap --optimizer adam --adam-eps 1e-06 --adam-betas '(0.9, 0.98)' --lr-scheduler polynomial_decay --lr 3e-05 --min-lr -1 --warmup-updates 2500 --max-update 40000 --dropout 0.3 --attention-dropout 0.1 --weight-decay 0.0 --max-tokens 768 --update-freq 2 --save-interval 1 --save-interval-updates 8000 --keep-interval-updates 10 --no-epoch-checkpoints --seed 222 --log-format simple --log-interval 2 --reset-optimizer --reset-meters --reset-dataloader --reset-lr-scheduler --restore-file $PRETRAIN --langs $langs --layernorm-embedding --ddp-backend no_c10d --save-dir ${SAVEDIR}
In a few minutes you’ll start to see a decent perplexity (better than after 12 hours of training from random); and after a few hours you’ll get a SOTA checkpoint.
I also had some trouble with actually loading the fine-tuned checkpoint to play with it interactively as the repo only shows you how to evaluate on a data file.
First you’ll have to copy the following files to one directory: checkpoint.pt (your fine-tuned checkpoint), the two language dictionaries (in my case dict.ja_XX.txt and dict.en_XX.txt) and sentence.bpe.model from the original checkpoint.
The actual code you need to evaluate the model in python is very simple when you know what you need to do (we just use the original BART hub interface with sentencepiece tokenization. The problem is it’s not documented anywhere so I had to read through all the code. Lucky you I will just give you the code you need so let’s actually generate some translations:
from fairseq.models.bart import BARTModel
BASEDIR = 'your_directory'
bart = BARTModel.from_pretrained(
'BASEDIR',
checkpoint_file='checkpoint.pt',
bpe='sentencepiece',
sentencepiece_vocab=f'{BASEDIR}/sentence.bpe.model')
bart.eval()
sentence_list = ['旅行に来る外国人はこれからも少ないままになりそうです。このため、日本の経済はとても厳しくなっています。']
translation = bart.sample(sentence_list, beam=5)
print(translation)
breakpoint()
Note that the sample method does not insert </s> between two sentences as is expected from the training procedure. So if you really want to respect the correct data distribution you need to call encode directly and then generate and decode as in the sample function. From my testing, however, it did not seem to make any difference to translation quality.
The above example outputs:
"The number of foreign tourists coming to Japan will continue to be small, and this is why Japan's economy is becoming so severe.[en_XX]"
This is a challenging sentence to translate, and I’d say mBART is actually slightly better than deepl or google translate:
| mBART | The number of foreign tourists coming to Japan will continue to be small and this is why Japan’s economy is becoming so severe. |
| deepl.com | It is likely that the number of foreigners who come to travel will continue to be low. This has made the Japanese economy very difficult. |
| translate.google.com | The number of foreigners who come to travel is likely to remain low. Because of this, the Japanese economy has become very difficult. |
Enjoy your SOTA translation model! Questions? Reach out to me on twitter @tmramalho.